对第 30 届神经信息处理系统大会(NIPS 2016)中百度首席科学家吴恩达教授的演讲Nuts and Bolts of Building Applications using Deep Learning,做的笔记。最重要内容是 偏差/方差(bias/variance)分析框架。
深度学习的崛起
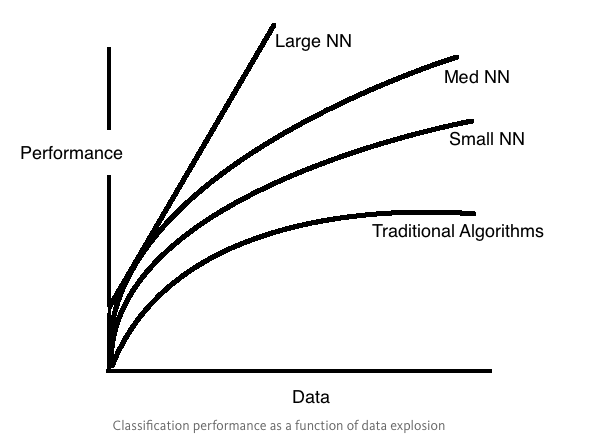
吴恩达在开场提到:深度学习为何这么火?答案很简单:因为数据规模正在推动深度学习的进步。
从图中得到的:
- 不同于传统机器学习模型,对 DL 来说,数据量和 performance 几乎是线性的关系
- 在小数据集部分(small data regime),也就是 x轴最左边,不同方法的差别是非常小的,然而随着数据量的增大,变化就非常快了
吴恩达还提到了一点,你为了某个 task 去得到/使用一个数据集是一回事,你去维护这个数据集让它 scaleable 又是另一回事。所以对商业应用,一般需要两个团队,系统团队(systems team)和算法团队(algorithms team)。
主要的 DL 模型
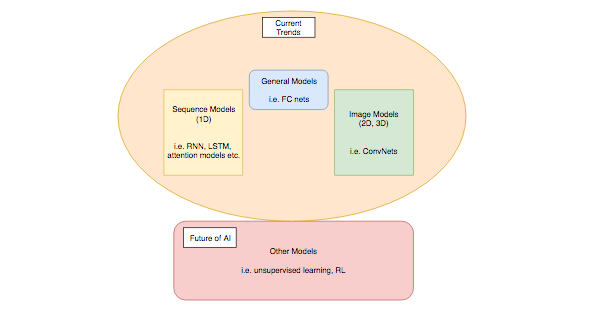
- 普通神经网络(General DL)
全连接模型 - 顺序模型(Sequence Models) (1D 顺序)
RNN, GRU, LSTM, CTC, 注意力模型 - 图像模型(Image Models)
CNN - 未来的 AI(Unsupervised and Reinforcement learning)
无监督学习(稀疏编码 ICA, SFA,)增强学习
端到端的学习
AI 工程师并不用花很多时间在特征工程或者说中间层的特征表达上(intermediate representations),而是可以直接从一端(原始输入)到另一端(输出)。另外,DL 能产生的不是一个简单的数字(i.e. a class prediction),它还能产生特征向量。比如在图像标注(Image captioning)中,CNN 用来产生输入图像的特征向量,然后这个向量又会被作为 RNN 的主要输入,来为图像产生标注(caption)。另外的例子如翻译、语音识别,图像生成等。
这看起来很简单,貌似 DL 就可以完全取代之前的 ML 模型了?并!不!是! 始终要记得一个前提,这种端对端的方法只有在数据量足够大的时候才能有好的表现,所以,如果大的数据集很难获得,那么就要用 DL 模型就要很谨慎了。在实践过程中,并不是所有的场合都有大的标注数据集,所以加入了人工设计的特征信息(hand-engineered information)和领域知识(feild expertise)的模型往往占了上风。
深度学习策略
一个机器学习工程师在建模的时候会有很多问题:
- 什么时候去找更多的数据?
- 要不要用更长的时间去训练?
- 什么时候要重新思考一下架构(architecture)?
- 什么时候引入/丢掉正则项?
…
为了系统解决这个问题,Ng 带来了一个 偏差/方差(bias/variance) 分析框架。
数据集划分
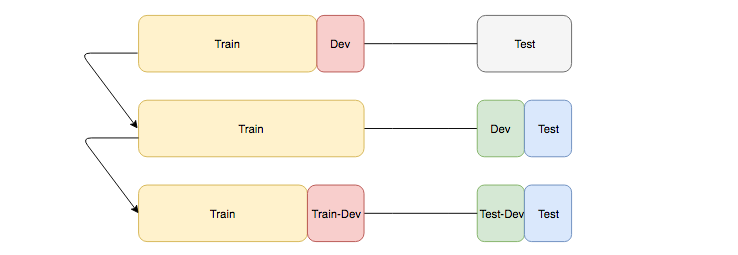
在大多数的 DL 问题中,训练集和测试集通常来自不同的分布,这种情况下,将数据分成 train/dev/test 可能会有点 tricky。有些人可能会从训练集中砍一部分来做开发集,如第一行。而实际上这样的效果是很差的,因为通常意义上来说,我们希望我们的开发集和测试集来自同一个分布,否则,很有可能工程师花费很多很多的时间在开发集上进行调参,然而测试集和开发集上的结果非常的不同,就浪费了很多精力。
因此,聪明的做法是像图中的第二行,将测试集分为 dev/test 两部分。Ng 建议说,在实践中,可以对两个分布的数据集都划分一部分作为开发集,如第三行的图,这样,不同错误之间的 gap 可以帮助我们更好的分析问题(如下图)。
错误分类
先来了解一下三种错误
- 人类水平误差(human level error)
- 训练集误差(training set error)
- 开发集误差(validation set error)
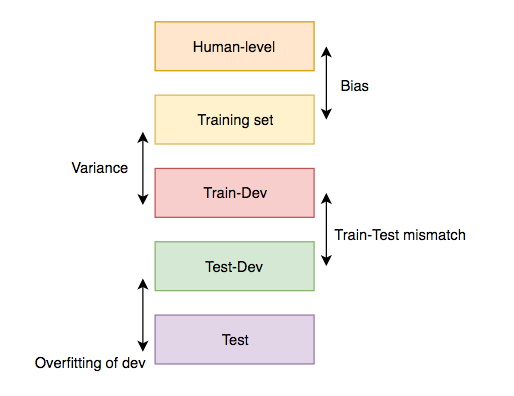
高偏差(high bias)
来看一下 高偏差(high bias),对应的问题是 underfitting,训练集的错误率就很高,这种情况下,需要建立更大的模型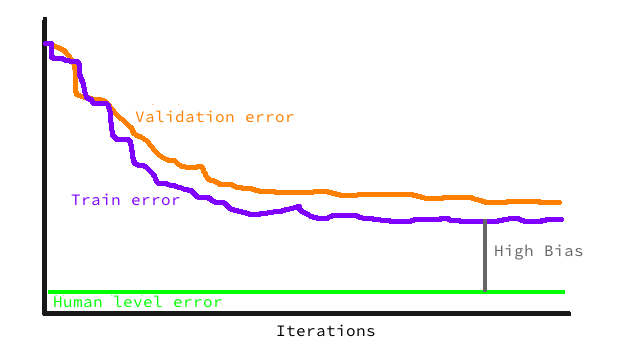
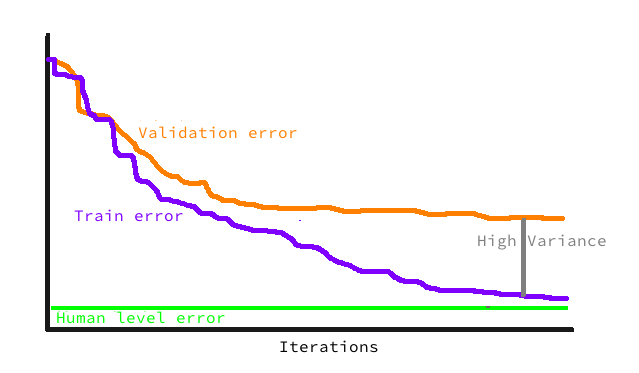
高方差(high variance)
高方差(high variance),对应的问题是 overfitting,在训练集上表现的非常完美,然而开发集和测试集却有很高的错误率。下一步是引入正则或者多加些数据来调优。
高偏差和高方差
高偏差(high bias) 和 高方差(high variance) 都很高的话,就要多加入数据,或者重新设计一下架构(或者用新的模型)了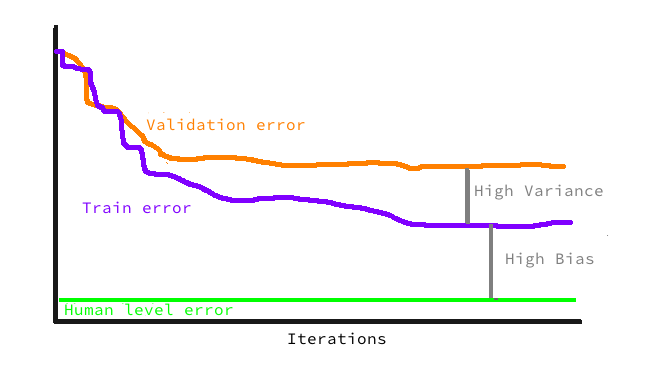
分析框架
所以分析框架就来了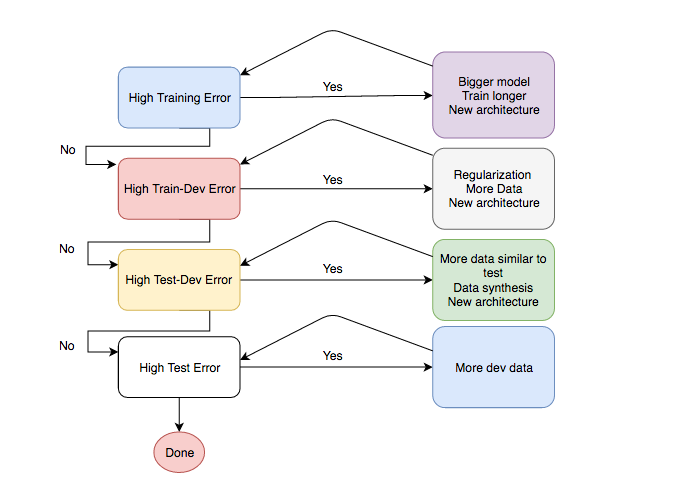
中文版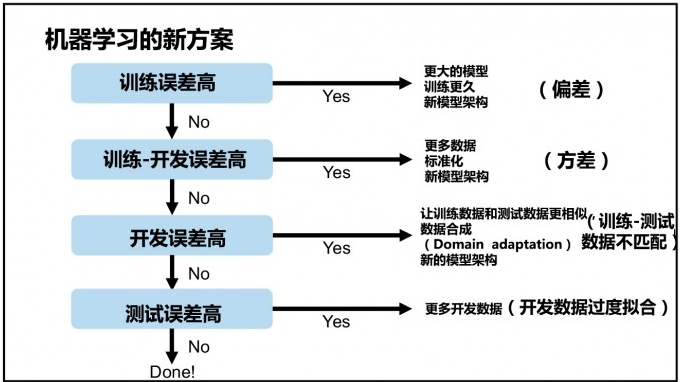
人类的表现水平
当 DL 在处理某项任务上比人类表现还差时,你经常会看到最快的进步,而当它能达到甚至超越人类的精度后,模型就应该趋于稳定了(意思说我们就不要再去动它了)。为什么呢?因为数据集会有一个理论上的”极限”,之后对模型的种种优化很有可能只是无用功,另外,人类往往很擅长做这些任务,要超过人类的表现,从边际收益看太不划算了。
再次重申下,人类水平的误差和贝叶斯最优误差不是一回事,如果你不知道这一点,那么很可能在训练模型后的下一步做无用功。
举个例子,一个图像识别的任务,如果下图左下角的表现,也就是 train error: 8%,dev error: 10%,而人类水平的误差是 1%,那么你可以尝试增加模型大小,增加训练时间等方式来提升模型,然而如果人类水平的误差是 7.5%,那这更多的是一个方差的问题,你可能需要花更多时间来合成数据,或者找和测试集更相似的数据来训练模型。
顺便提一句,总是有优化空间的,即使已经达到了人类水平的精度,也总有一些数据子集效果不怎么好,可以在这上面努力。
最后,说一下怎么来定义人类水平的误差,以医疗领域的图像标签任务为例,有下面的集中误差,选哪一个作为人类水平误差?
- 普通人类(typical human): 5%
- 普通医生(general doctor): 1%
- 专家医生(specialized doctor): 0.8%
- 专家会诊(group of specialized doctors): 0.5%
答案是选最后一个,因为和贝叶斯最优误差最接近。
学习建议
最后,Ng 提出了两点建议,来帮助大家提高作为 DL 工程师的能力。
- Practice, Practice, Practice: 参与 Kaggle 的竞赛,多读相关的博客,参与论坛讨论…
- Do the Dirty Work: 读大量的论文,做实验尝试去得到和论文一样的结果,很快,你就会有自己的想法,建自己的模型啦~
参考链接:
Nuts and Bolts of Applying Deep Learning (Andrew Ng)
Nuts and Bolts of Applying Deep Learning — Summary
Nuts and Bolts of Applying Deep Learning

